SPFresh: Incremental In-Place Update for Billion-Scale Vector Search
Introduction
There is a strong desire to support fresh update of vector indices because current systems generate a vast amount of vector data continuously in various settings. For example, 500+ hours of content are uploaded to YouTube every minute, one billion new images are updated in JD.com every day, and 500PB fresh unstructured data are ingested to Alibaba during a shopping festival.
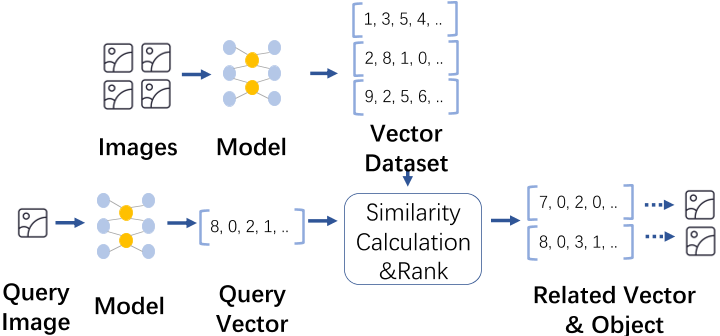
Fresh updates require vector indices to incorporate new vectors at unprecedented scale and speed while maintaining their high-quality to produce low query latency and high query accuracy of approximate vector searches.
To scale to large vector datasets with lower costs, this paper presents SPFresh, a disk-based vector index that supports lightweight incremental in-place local updates without the need for global rebuild.
The core of SPFresh is LIRE, a Lightweight I ncremental REbalancing protocol that accumulates small vector updates of local vector partitions, and re-balances local data distribution at a low cost.
LIRE Protcol Design
The LIRE (Lightweight Incremental REbalancing) protocol is the core component of the SPFresh system, designed to support incremental in-place updates for large-scale vector search indices without the need for global rebuilds. Here’s a detailed breakdown of the LIRE protocol design:
1. Background and Objectives of LIRE
- Background: Maintaining an efficient Approximate Nearest Neighbor Search (ANNS) system for high-dimensional vector data requires the ability to handle continuously growing data volumes and support updates to the vector index. Traditional graph-based index updates are costly as they may require examining the entire graph for each insertion or deletion.
- Objectives: LIRE aims to maintain index quality through local updates by only reassigning vectors at the boundaries, thus achieving low-overhead updates and preserving query latency and accuracy.
2. Core Operations of LIRE
The LIRE protocol encompasses five fundamental operations: Insert, Delete, Merge, Split, and Reassign.
- Insert: New vectors are directly inserted into the nearest partition (posting).
- Delete: Ensures that deleted vectors do not appear in search results and are eventually removed from the corresponding postings.
- Merge: When a posting falls below a certain size threshold, LIRE identifies the nearest posting for merging, combining them into one.
- Split: If a posting exceeds a length limit, LIRE evenly splits the oversized posting into two smaller ones.
- Reassign: After a split or merge, reassigns vectors in the nearby postings to adapt to changes in data distribution.
3. Challenges in Reassigning Vectors
Reassigning vectors can be costly as it requires expensive changes to on-disk postings. Therefore, it is crucial to identify the correct set of neighboring postings to avoid unnecessary reassignments.
4. Conditions for Vector Reassignment
LIRE uses two necessary conditions to determine whether a vector should be reassigned:
- Condition 1: A vector in the old posting should consider reassignment if:
𝐷 (𝑣, 𝐴𝑜 ) ≤ 𝐷 (𝑣, 𝐴𝑖 ), ∀𝑖 ∈ 1, 2 - Condition 2: A vector in a nearby posting should consider reassignment if:
𝐷 (𝑣, 𝐴𝑖 ) ≤ 𝐷 (𝑣, 𝐴𝑜 ), ∃𝑖 ∈ 1, 2
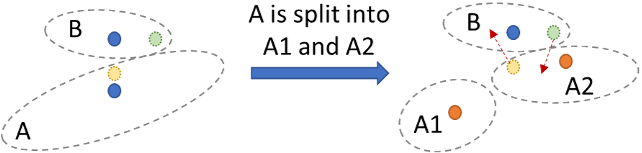
5. Convergence of Split-Reassign Actions
LIRE protocol ensures that split and reassign actions will converge to a final state and terminate in a finite number of steps. Please read the original article for a more detailed proof process.
SPFresh Design and Implementation
Overview
SPFresh’s architecture includes three new modules to implement LIRE:
- In-place Updater: Responsible for appending new vectors to the tail of their nearest postings and maintaining a version map to track vector deletions.
- Local Rebuilder: Maintains a job queue for split, merge, and reassign jobs and dispatches these jobs to multiple background threads for concurrent execution.
- Block Controller: Handles posting read, write, and append requests, as well as posting insertion and deletion operations on disk.
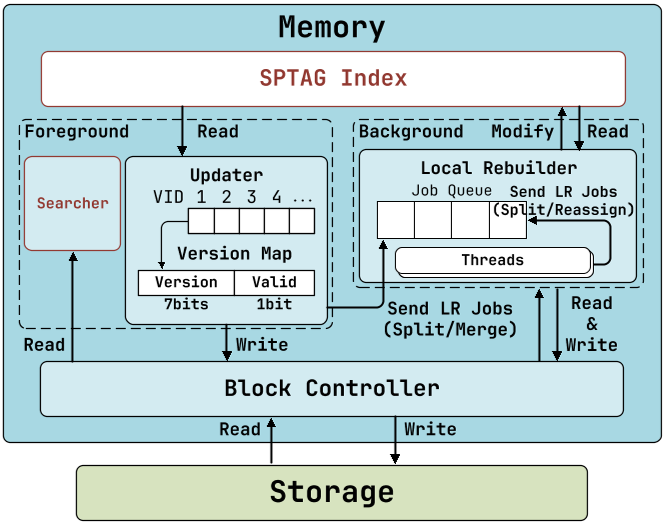
Updater Design and Implementation
Role: The Updater is responsible for handling incoming vector updates by appending new vectors to the nearest postings and managing deletions through a version map.
Key Features:
- In-place Updates: New vectors are appended directly to the tail of their nearest postings, ensuring that updates are performed in-place without the need for global index rebuilds.
- Version Map: Maintains a version map to trace vector deletions. This map is used to prevent deleted vectors from appearing in search results and to manage the replicas of each vector.
- Split Detection: Monitors the length of postings and sends split jobs to the Local Rebuilder when a posting exceeds a predefined length limit.
Local Rebuilder Design and Implementation
Role: The Local Rebuilder is the core component that implements the LIRE protocol, managing split, merge, and reassign operations in the background.
Key Features:
- Job Queue: Maintains a queue for split, merge, and reassign jobs, which are dispatched to multiple background threads for concurrent execution.
- Split Operation: Triggered by the Updater, it cleans up deleted vectors and splits oversized postings into smaller ones if necessary.
- Merge Operation: Identifies and merges nearby undersized postings into a single posting.
- Reassign Operation: Checks and rebalances the assignment of vectors in newly split or merged postings and their neighbors to maintain data distribution balance.
- Concurrency Control: Implements fine-grained posting-level write locks to ensure atomic updates to postings and uses compare-and-swap (CAS) operations for concurrent reassignment.
Block Controller Design and Implementation
Role: The Block Controller is a lightweight storage engine optimized for reading, providing append-only operations on postings and directly operating on raw SSD interfaces.
Key Features:
- SPDK-based Implementation: Leverages the raw block interface offered by SPDK (Storage Performance Development Kit) to bypass the legacy storage stack and perform direct SSD I/O operations.
- Storage Data Layout: Consists of in-memory Block Mapping, a Free Block Pool, and a Concurrent I/O Request Queue.
- Block Mapping: Maps posting IDs to SSD block offsets, implemented as an in-memory dense array for efficient lookup.
- Free Block Pool: Manages free SSD blocks for allocation and garbage collection of stale blocks after split and reassign operations.
- Concurrent I/O Request Queue: Uses an SPDK circular buffer to send asynchronous read and write requests to the SSD device, maximizing I/O throughput and minimizing latency.
- Posting APIs:
- GET: Retrieves posting data by ID, looking up block mapping and sending asynchronous I/O requests to fetch the desired blocks.
- ParallelGET: Reads multiple postings in parallel to amortize the latency of individual GETs, ensuring fast search and update.
- APPEND: Adds new vectors to the tail of a posting by allocating new blocks, reading the last block if not full, appending new values, and writing it as a new block.
- PUT: Writes a new posting to SSD by allocating new blocks and writing the entire posting in bulk, then updating the Block Mapping entry atomically.
Crash Recovery in SPFresh: Simplified Summary
Snapshots and WAL:
- SPFresh uses periodic snapshots of in-memory and on-disk data structures to capture system states.
- Updates between snapshots are logged in a Write-Ahead Log (WAL) for recovery purposes.
Recovery Process:
- In case of a crash, SPFresh recovers from the latest snapshot.
- The WAL is replayed to apply updates since the last snapshot.
- The WAL is deleted after a new snapshot is created.
Benefits:
- The recovery process is efficient and space-saving, as it only requires a small amount of disk space and recovers quickly from known states.